Text Encoding Initiative
Yet each man kills the thing he loves
By each let this be heard.
Some do it with a bitter look,
Some with a flattering word.
The coward does it with a kiss,
The brave man with a sword!
Oscar Wilde, The Ballad of Reading Gaol
This book studies texts and the things that computers can do with them. But, as you read along, you may notice that they cannot do all that much. Many of the methods that you will learn are simply sophisticated ways of counting words, whereas reading entails far more complicated processes of interpretation and analysis. When we read, we tend to skip to much more complicated understandings of a text:
-
What does it mean?
-
What elements of the text convey meaning? How do they do so?
Computers have a hard with abstract concepts like this. Computers tend to work in hierarchies and clear-cut structures, and, even then, they only know about those structures that someone has told them about. For example, if we were to say to a computer, “Hey! Find me the poem in this lesson!” It would have no idea what we were talking about: we have to find some way of telling the computer where it can find the poem. Right now it just thinks the text up there is no different from the other lines of text on this page. It’s all just text.
A computer program looking at the above passage from Oscar Wilde’s The Ballad of Reading Gaol would, most likely, not even recognize those six lines as related in any way. Nor it would understand anything about how the internal components of those lines are connected to each other. There are a number of ways to represent such structural information, and we can get towards one that works for a computer by working through a system that you might use on your own when you read.
Think about all the annotations that you put on your own pages as you read them. If you are anything like us, your markings tend to be all over the place. But imagine if you were to systematically note certain structural features of the text. We can think of the Wilde passage, after all, as a series of nested concepts:
- There is a stanza.
- This stanza contains some lines.
- Each line has text.
- Some of that text contains a rhyme.
And we can represent it graphically, like so, where a black line denotes the bounds of the stanza, a horizontal blue one represents the lines, and the rotating colors under the final words describe a rhyme scheme:

But you would probably need a moment to figure out what was going on if you came to this having not highlighted things yourself. We can do better. The following text annotations are a bit clearer and get closer to something we could understand without having any context. In fact, you may have worked with annotations like these before if you’ve taken a poetry class:
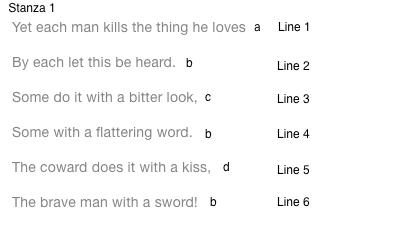
For a computer to understand this, we need an even more delineated way of describing the passage. We have to pay careful attention to syntax, the ways in which we mark particular things to provide information to the computer. Computers require very specific systematic guidelines to be able to process information, as you will learn in our chapter on “Cyborg Readers”. For example, we would have to consistently use lower-case letters to represent rhyme schemes. And “line 1” to represent the first line of a poem instead of “line one.” We need a clear and uniform way for describing the parts of the poem that never changes. Any variations from these rules would cause unwanted and unintended effects. Scholars have been working for years to develop such a system for describing texts in a way that can be processed by software. The Text Encoding Initiative (TEI), the result of this work, is an attempt to make abstract humanities concepts legible to machines. If we apply TEI to the passage, it might begin to look something like this:
<lg>
<l>Yet each man kills the thing he loves</l>
<l>By each let this be heard.</l>
<l>Some do it with a bitter look,</l>
<l>Some with a flattering word.</l>
<l>The coward does it with a kiss,</l>
<l>The brave man with a sword!</l>
</lg>
Notice how our concepts like ‘stanza’ and ‘line’ have here translated into particular tags:
- Our stanza becomes marked by
(line grouping). - Our lines become marked with
(line). - Each set of tags has both an opening (
) and a closing ( ) tag. - Closing tags are almost identical to opening tags except for a forward slash - /.
- Tags have intuitive relationships to the concepts that they represent:
corresponds to line, and corresponds to line group.
The opening and closing tags wrap around and determine the locations of particular structural elements for the computer: a line exists from here to there, a stanza exists from here to there, and so on. And take note of how certain tags can exist inside others. These framing elements help the computer understand the boundaries of the concepts we are describing, and they help to provide structure to the text. Think of TEI as a new layer that exists on top of the text. Words offer one layer of meaning, but we add new layers by marking the text up with these fixed annotations. This markup gives the computer (or future readers) more nuanced ways of understanding how the parts in a text relate to one another.
We can give further details to the poem. For example:
<lg type="poem">
<lg type="stanza">
<l>Yet each man kills the thing he loves</l>
<l>By each let this be heard.</l>
<l>Some do it with a bitter look,</l>
<l>Some with a flattering word.</l>
<l>The coward does it with a kiss,</l>
<l>The brave man with a sword!</l>
</lg>
<lg type="stanza">
<l> A short second stanza that we've made up.</l>
</lg>
</lg>
Here we’ve added an extra stanza group as well as an outer tag to denote that this is, in fact, a poem. We also give attributes to certain tags to provide more information about them: type=”stanza” tells the computer that the contents of this tag refer to a poem. Remember the nested hierarchy we talked about earlier? Notice how we represent it graphically by indentation. The outer poem element contains two stanzas, which contain some lines, and those have some text. You can run your eye down the text and see the structure. Some programming languages will actually error if you do not pay attention to such things. But, either way, it just helps us keep things clean and easy to read.
One last thing. Remember our rhyme scheme and line numbers? We can encode those too:
<lg type="stanza">
<l n="1" rhyme="a">Yet each man kills the thing he <rhyme>loves</rhyme></l>
<l n="2" rhyme="b">By each let this be <rhyme>heard</rhyme>.</l>
<l n="3" rhyme="c">Some do it with a bitter <rhyme>look</rhyme>,</l>
<l n="4" rhyme="b">Some with a flattering <rhyme>word</rhyme>.</l>
<l n="5" rhyme="d">The coward does it with a <rhyme>kiss</rhyme>,</l>
<l n="6" rhyme="b">The brave man with a <rhyme>sword</rhyme>!</l>
</lg>
We have added attributes to denote the line numbers for each line as well as the rhyme scheme, and then a new
Once a text has been encoded in this way, it can be represented more easily in a digital form. This work may not necessarily actually make it look any different. But it does allow you to do new and exciting things to your work. TEI encoding can make it possible to provide nuanced digital editions of a text. We could actually say to a program, pull out all the rhyming words in a poem. Or make them appear differently on a webpage. Or change them all to “TEI is the best.”
Let’s look at an example of something that’s got a lot of encoding already in it. Here is the TEI for this entry on a robbery case that mentions Jack the Ripper from the Old Bailey Online. You might not recognize a lot of the tags (there are loads of TEI tags), but the general arrangement of them should look familiar (full TEI here):

Focus on what you do know: the tagging syntax should ring some bells. If you want to look up any of the tags, you can always check out the TEI guidelines. A lot of working with technology consists of not panicking when you see something unfamiliar and then looking up what you don’t know. But we digress.
When you look at the public-facing version of the entry on the Old Bailey Online, almost all the tags disappear:

In order to make the text legible for readers, we very often hide most (or all) of the markup that is helping to present the document. This ensures that you can serve the needs of different audiences: some people might want to see the TEI for your text, but others might just want to be able to read it as normal. We have already talked a bit about the functions you can get from TEI, but, if they largely remain hidden, you might find yourself thinking that they might not be enough to warrant the amount of work that goes into putting together a TEI-encoded text.
Looking at the TEI tags for this document give you a sense of why you might encode a text even if not many people are going to look at the TEI. You’ll see there are tags for the witnesses’ names (both first and last) and their gender. Why might this be useful? Well, maybe the people who designed this site thought that users could conceivably want to search for the participants in a crime by name and by gender. That way you can ask all sorts of questions about what other crimes individuals witnessed, or whether men or women were more likely to be involved in or witness to particular types of crime.
Encoding is meant to convey abstract humanities concepts to the machine so that we can make better use of them in our digital work. Some of these concepts, like line breaks, might be pretty clear cut. Others might require a lot of interpretation. Even given the same set of tags and texts, two people could encode things differently. You can make a whole career off working with TEI, and we have just scratched the surface here. But encoding documents in TEI is an important step in preparing them for their lives as digital artifacts. Not all texts need to be encoded in TEI in order for them to be archived, but the vast majority of documents you will find in digital humanities archives have been encoded in this way. The process helps ensure that complex humanities data makes its way comfortably, ethically, and responsibly into the digital world.
Further Resources
- Jacob Heil is great on the intellectual reasons for encoding in “Why We TEI.”
- Ryan Cordell in “On Ignoring Encoding” gives a great defense of textual encoding as a fundamental part of digital humanities.